点击纠错
点击纠错
gemini人工智能支持处理和理解文本、代码、音频、图像、视频等多种信息模态的协同推理能力。接受图文混合内容、带语音的指令或者视频片段作为输入,进而生成连贯的文本、代码或其他格式的回答。该模型系列依据规模和用途的不同,划分出多种版本,像功能强大的Gemini Ultra、均衡通用的Gemini Pro以及轻量高效的Gemini Nano都在其中。用户既可以通过独立的聊天机器人界面使用,也能在Google AI Studio开发平台,以“帮我写作”等助手功能的形式来获取服务。
1.拥有原生的多模态理解能力,能够同时对文本、图像、音频和视频信息进行处理并开展关联分析。
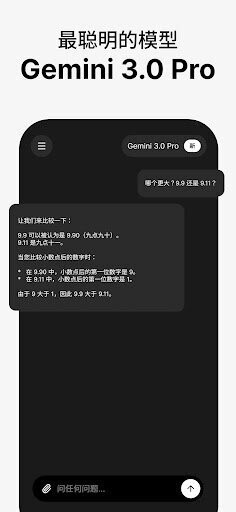
2.复杂的推理能力,使得在解决数学、物理以及逻辑链条较长的问题时,能够展现出清晰的思维过程。
3.模型在代码生成、解释、调试以及不同编程语言间的转换任务上,呈现出较高的准确度与实用性。
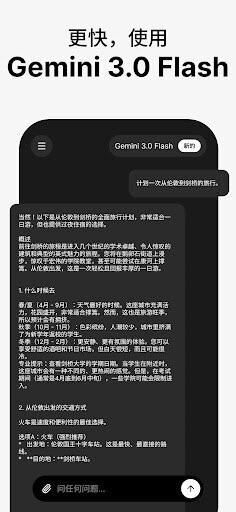
4.强大的上下文窗口,让它能够处理并记忆超长的对话历史或文档内容,从而保持回答的一致性与连贯性。
5.模型家族提供了从云端部署到设备端运行的不同规模版本,以此适应从研究到消费级产品的多样化需求。
1.开发者借助Google AI Studio平台,能够便捷地访问模型API,进而构建自己的AI驱动应用程序。
2.模型能力被整合进Google Workspace,在Gmail、Docs等工具中,为用户提供写作、总结和头脑风暴方面的辅助。
3.轻量化的Gemini Nano模型,可直接在部分高端Pixel手机上运行,实现设备端的智能回复建议。
1.它能够理解上传的图像内容并回答相关问题,也可以根据图文混合指令生成创造性的文本内容。
2.在编程协助场景中,它能依据描述生成代码片段,解释现有代码的功能,或者帮助查找其中的错误。
3.回答通常具有结构清晰、信息量大的特点,并且能够根据用户的后续追问,进行深入的拓展、调整或解释。
1.软件借助尖端智能算法构建,输入问题就能获取相应回答
2.通过拍照的方式可获取更多信息
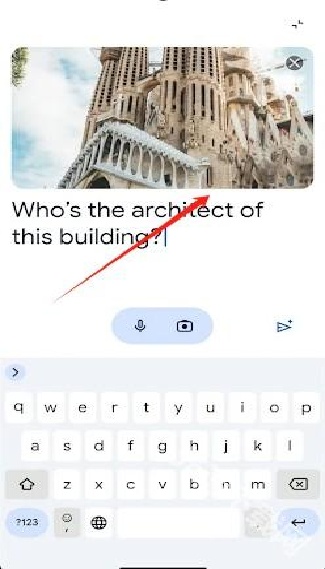
3.软件具备专业的文本内容,能为你的写作提供较大帮助
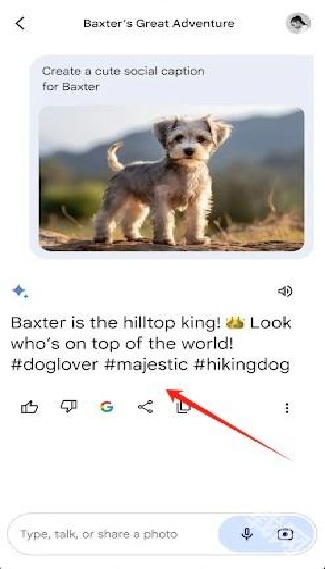
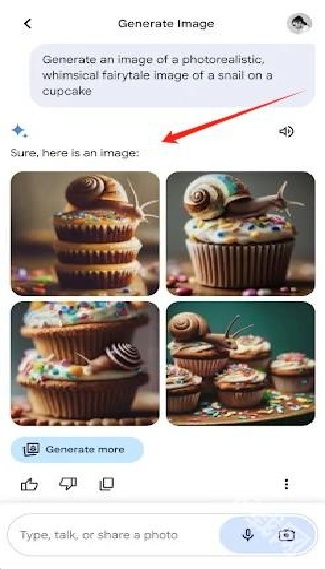
4.在此处输入文字能够生成图片,所有图片均可自由下载分享模型
Gemini人工智能把文本、代码、图像等多模态理解能力从“拼接组合”的状态提升至“原生统一”的层面,这种设计让其在处理需要跨模态推理的现实世界任务时,逻辑更为连贯,蕴含的潜力也更大。它在复杂推理和编程任务中展现出的强劲能力,使其不再仅仅是一款聊天工具,更成为能够协助解决学术、技术和创意问题的强大思考伙伴。
同类推荐
最新录入